Planning the future for Curie
Our working horse Curie is up for quite a long time running oldstable Lenny more than a year without restart (all kudos to Hetzner), and I think it should get crispy Squeeze soon.
curie:/$ uptime
22:43:13 up 418 days</pre>
During initial install in 2010 we made several mistakes in configuration because of rush, that I would like to correct with upcoming upgrade. However, some prior planning to be applied to minimize the downtime in this case.
First, the list of main issues in current configuration:
- Too many services w/o proper isolation (e.g. bind, web, db, mail, etc … are here).
- Bad (read, no) proper service monitoring.
- No service priorities agreed (e.g. client production sites and personal test polygons running together by the same service).
- Inability to perform restarts or disk checks without stress due to the lack of physical access to the machine.
After some head scratching virtualization looks like to be the proper way to avoid the above stated problems. Below is the conceptual idea and topology for re-organization of services running on curie.
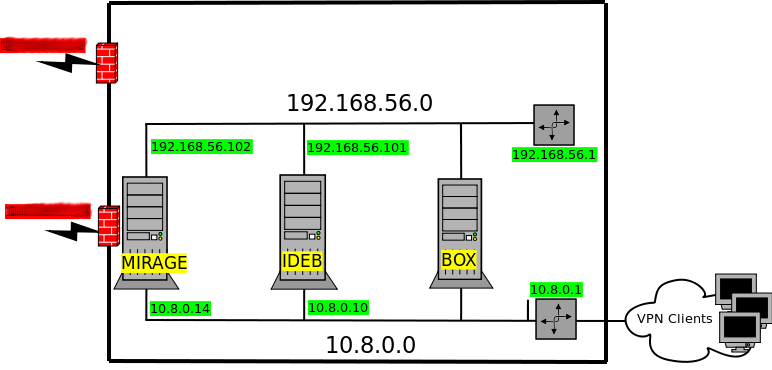
The key points are the following:
- Most services to be moved to VMs. Only monitoring and internal stuff should remain.
- Service should communicate over internal network and also over VPN.
- Some VMs will be accessible from the wild as well.
Sounds great … But I have still not answered myself if all this migration is really worth the effort :).