On the crest of streams with Flink

Photo by Fabrizio Chiagano on Unsplash
Stream processing and Apache Kafka
Stream processing and Apache Kafka is Klarna’s essential piece of infrastructure that enables engineering data-driven culture and the ability to move forward with our new projects quickly.
At Klarna decision services, we rely heavily on Kafka to process millions of data points streaming to us every day. We need to be able to provide easy to use ad-hoc analytics, aggregate these data points as they stream into our systems and also run arbitrary transformations to compute features and variables used later in the decisioning process, alert events and anomalies.
Apache Flink and AWS Kinesis Data Analytics
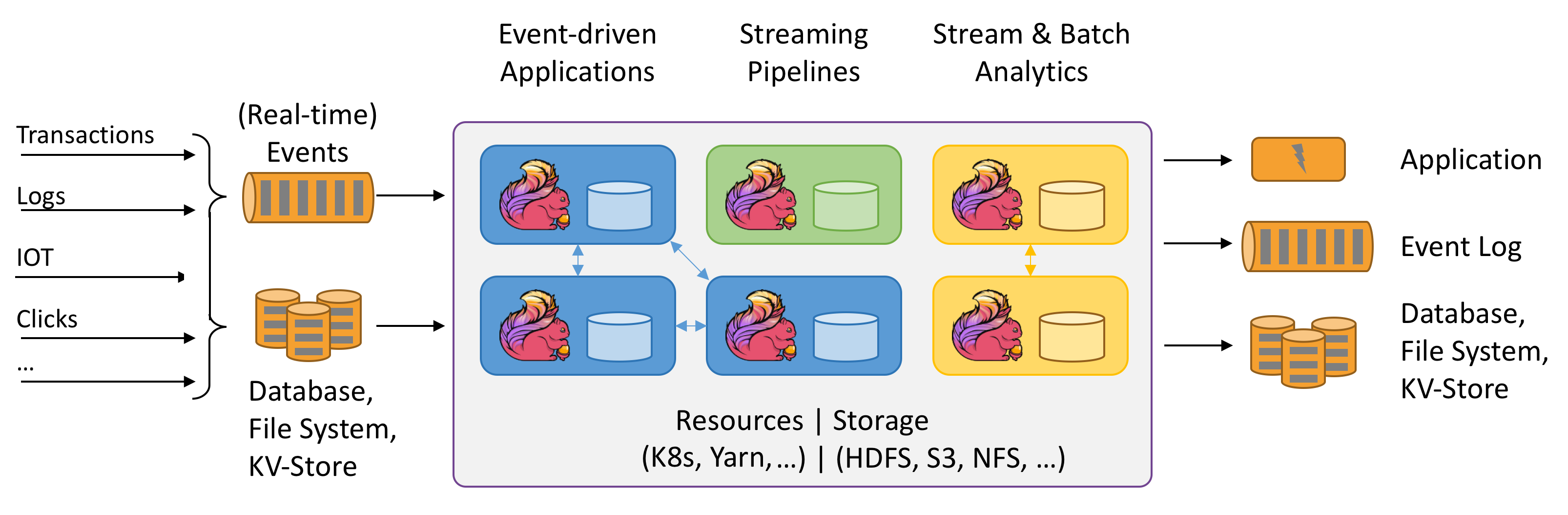
Apache Flink is a scalable and fault-tolerant processing framework for streams of data based on the idea that it should not be hard to express computations (like AVG or GROUP BY) while still be able to scale indefinitely, in a fault-tolerant manner.
In its core, it is the JVM based framework that was developed specifically for stateful computations over data streams. The project itself has an active open source community, both used and contributed by many companies that require to process large amounts of data.
Kinesis Data Analytics was announced by AWS In November 2019.
It is an AWS managed runtime environment for Apache Flink applications. Since that time using Apache Flink on AWS Kinesis Data Analytics is getting momentum for us given it important features:
- supports checkpoints and snapshots, that allows easy recovery from the offset that we reached in Kafka
- treats batch data sources and streaming data sources same way, so we can use the same implementation for backfill and streaming parts of our pipeline
- low latency computations with autoscaling options by AWS Kinesis Data Analytics
- Java-based on out-of-the-box integration with Apache Kafka, Kinesis Data Streams and Apache Avro.
Flink connector for Kafka
In this article, I will be sharing our experience and key learnings of using Amazon Kinesis Data Analytics and Flink for processing Kafka events encoded using Apache Avro and discuss how to implement custom deserialization schema in Flink and why you might need that.
As the driving use case consider the solution that is responsible for a) ingesting trace events from different decision services via data consumption from different Kafka topics, b) making some non-sophisticated data massaging, and c) persisting the data for later ad-hoc analysis.

Flink provides Apache Kafka connector for reading data from and writing data to Kafka topics out of box using FlinkKafkaConsumer.
In order to use FlinkKafkaConsumer you normally configure
- The topic name / list of topic names
- A
DeserializationSchemafor deserializing the data from Kafka - Properties for the Kafka consumer, e.g.
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "");
properties.setProperty("group.id", "");
Example of using FlinkKafkaConsumer in you application
DataStream<String> stream = env.addSource(
new FlinkKafkaConsumer<>(
"topic",
new SimpleStringSchema(),
properties));
In order to define how to turn the binary data in Kafka into Java/Scala objects you need to select the implementation of DeserializationSchema
Flink provides the following schemas out of the box
- JsonNodeDeserializationSchema (from
org.apache.flink:flink-jsonlibrary) that turns the serialized JSON into an ObjectNode object - AvroDeserializationSchema (from
org.apache.flink:flink-avrolibrary) that reads data serialized with Avro using a statically provided Avro schema - ConfluentRegistryAvroDeserializationSchema (from
org.apache.flink:flink-avro-confluent-registrylibrary) that reads data serialized with Avro using a statically provided reader schema and lookups the writer’s schema in schema-registry.
Custom DeserializationSchema
The main challenges that required us to implement custom deserialization schema for our use case were the following:
- One service can emit events using different (thus backward compatible) type versions into the same topic
- Multiple different services can emit events into the same Kafka topic using different trace types
- All data points from trace event should be persisted in the database, so it is not technically feasible to stick to particular reader schema
- Existing https://issues.apache.org/jira/browse/FLINK-11030 (“Cannot use Avro logical types with ConfluentRegistryAvroDeserializationSchema”) affecting us as producers use Avro logical types.
Luckily Flink provides good abstraction for custom deserialization logic in the form of KafkaDeserializationSchema interface that you need to implement in order to provide you custom logic how to turn the binary data from Kafka into Java/Scala objects.
public interface KafkaDeserializationSchema<T> extends Serializable, ResultTypeQueryable<T> {
/**
* Method to decide whether the element signals the end of the stream. If
* true is returned the element won't be emitted.
*/
boolean isEndOfStream(T nextElement);
/**
* Deserializes the Kafka record.
*/
T deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception;
}
For our particular use case if was enough to use widely adopted io.confluent.kafka.serializers.KafkaAvroDeserializer from io.confluent:kafka-avro-serializer library.
class GenericKafkaDeserializationSchema implements KafkaDeserializationSchema<GenericRecord> {
private KafkaAvroDeserializer deserializer;
@Override
public GenericRecord deserialize(ConsumerRecord<byte[], byte[]> consumerRecord) {
return (GenericRecord) deserializer.deserialize(consumerRecord.topic(), consumerRecord.value());
}
@Override
public boolean isEndOfStream(GenericRecord nextElement) {
return false;
}
Important performance optimizations. Flink Serialization
Flink job exchanges data records between its operators. Records need to be serialized to bytes first, because the records may not only be sent to another instance in the same JVM but instead to a separate process. Also, Flink’s off-heap state-backend is based on a local embedded RocksDB instance which is implemented in native C++ code and thus also needs transformation into bytes on every state access. Please read Flink Serialization Tuning post for detailed explanation why wire and state serialization alone can easily cost a lot of your job’s performance if not executed correctly.
Apache Flink’s out-of-the-box serialization can be roughly divided into the following groups:
- Flink-provided special serializers - for basic types
- POJOs - a public, standalone class with a public no-argument constructor and all non-static, non-transient fields in the class hierarchy either public or with a public getter- and a setter-method
- Generic types - user-defined data types that are not recognized as a POJO and then serialized via Kryo.
Flink offers built-in support for the Apache Avro serialization framework (currently using version 1.8.2) by adding the [org.apache.flink:flink-avro] dependency into your job. However, it is important to note that Avro’s GenericRecord types cannot, unfortunately, be used automatically since they require the user to specify a schema. Unfortunately in our case, it is not possible because we need to use GenericRecord in and custom DeserializationSchema exactly due to lack of strictly defined Avro schema.
Without type information, Flink will fall back to Kryo for GenericRecord serialization which would serialize the schema into every record, over and over again. As a result, the serialized form will be bigger and more costly to create. We have observed a huge performance drop in terms of increased CPU load when dealing with records backed by complex Avro schemas.
Since Avro’s Schema class is not serializable, it can not be sent around as is. You can work around this by converting it to a String and parsing it back when needed or you can improve your KafkaDeserializationSchema by returning Tuple2 or Row entries instead.
The example below demonstrates the optimizations done in one of our projects where KafkaDeserializationSchema functionality was combined with the mapper operator to avoid GenericRecord deserialization happening between those operators.
Flink comes with a predefined set of tuple types that all have a fixed length and contain a set of strongly-typed fields of potentially different types. This certainly is a (performance) advantage when working with tuples instead of POJOs. Row types are mainly used by the Table and SQL APIs of Flink. A Row groups an arbitrary number of objects together similar to the tuples. Because exact field types are missing Row type information should be provided by the operator as well for effective serialization
@Override
public Tuple2<Boolean, Row> deserialize(ConsumerRecord<byte[], byte[]> consumerRecord) {
try {
GenericRecord deserializedRecord = (GenericRecord) deserializer
.deserialize(consumerRecord.topic(), consumerRecord.value());
return mapper.map(deserializedRecord);
} catch (Throwable t) {
LOGGER.warn("Error deserializing generic Avro record. {}", t.getMessage());
return null;
}
}
@Override
public TypeInformation<Tuple2<Boolean, Row>> getProducedType() {
return Types.TUPLE(Types.BOOLEAN, Types.ROW(Types.STRING,
Types.SQL_TIMESTAMP,
Types.STRING,
Types.STRING,
Types.POJO(PGobject.class),
Types.STRING,
Types.STRING,
Types.STRING,
Types.STRING,
Types.SQL_TIMESTAMP));
}
Additional optimizations. KafkaAvroDeserializer
You should strongly consider using Schema Registry Client with client-side caching, e.g.CachedSchemaRegistryClient.
Also, be aware of potential internal optimizations for KafkaAvroDeserializer related to caching DatumReader instances (version not yet released at the moment) fixed in the scope of this issue. The actual gains from the fix vary somewhat based on hardware and Java version used but are generally between ~3x and ~8x. The cause is expensive DatumReader and DatumWriter objects being instantiated per record serialized or deserialized due to a lack of caching. The result is a lot of wasted CPU resources as well as potentially capping pipeline throughput.
Conclusion
- Flink provides good out-of-box primitives to work with Kafka and Avro
- Flink provides good abstraction for custom deserialization logic
- We can process large amounts of data efficiently
- You can alway find ways to optimize